Noticias
Caos informático: Crowdstrike y Microsoft provocan un colapso mundial que afecta a aeropuertos, bancos y empresas
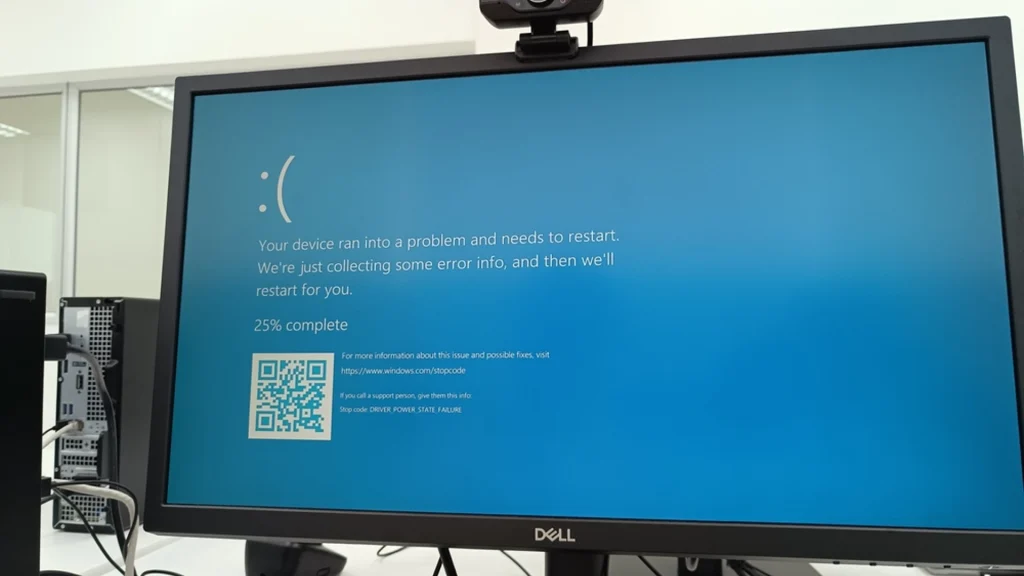
El viernes 19 de julio de 2024, un error en una actualización del software en un componente de la plataforma de seguridad Crowdstrike Falcon, provocó una interrupción global en los servicios de seguridad de la empresa, el famoso pantallazo azul de la muerte (BSOD). Esto afectó a millones de dispositivos Windows en todo el mundo, lo que provocó que las empresas y organizaciones no pudieran acceder a sus datos críticos.
El problema se ha producido debido a una actualización automática del agente Falcon de CrowdStrike (Falcon Sensor), la cual contenía un error que ocasionaba incompatibilidades con determinados sistemas Windows. Como resultado de este error, los dispositivos afectados experimentaron bloqueos y reinicios inesperados, lo que generó interrupciones significativas en las operaciones regulares. La incidencia impactó en una amplia gama de dispositivos, incluyendo ordenadores personales, servidores y dispositivos de red.
La respuesta de CrowdStrike
CrowdStrike reaccionó con celeridad para identificar la raíz del problema. Acto seguido, lanzaron una nueva actualización para corregir el error y comunicaron la situación a sus clientes de manera clara, transparente y directa. Además, ofrecieron soporte técnico a aquellos que lo requirieron y tomaron medidas para prevenir que este tipo de incidentes se repitan en el futuro.
La respuesta efectiva y oportuna de Crowdstrike sirve como modelo a seguir para otras empresas que se enfrentan a incidentes de seguridad. La comunicación transparente con los clientes, el compromiso para solucionar los problemas y la implementación de medidas preventivas son elementos esenciales para mantener la confianza y proteger la reputación de cualquier organización. Por contraposición, cabe destacar que los flujos definidos para el despliegue no han sido correctos porque si las pruebas hubiesen sido exhaustivas, no hubiese ocurrido este desastre tecnológico a nivel mundial.
El tipo de incidente
El incidente fue clasificado como un error de software no intencional. Este evento resalta la importancia de implementar una correcta gestión de riesgos, siendo este un componente fundamental de la gestión de seguridad de la información. En este sentido, poder abarcar las estrategias y prácticas orientadas a identificar, analizar, evaluar y mitigar los riesgos potenciales que puedan afectar la seguridad de la información y los sistemas informáticos de una organización.
Dependencia de tecnologías críticas
Las empresas no deberían depender de un solo proveedor de soluciones de ciberseguridad. Es importante tener una variedad de herramientas de diferentes proveedores para reducir el riesgo de que una falla en un solo sistema afecte a toda la organización. Tanto desde Crowdstrike y también desde Windows han puesto todos los remedios posibles, incluso generando una herramienta gratuita para poder realizar el proceso de recuperación de archivos/ficheros.
La historia se repite
CrowdStrike no es la primera ni la última solución de ciberseguridad que deja a sus clientes sin protección. En los últimos años, se han producido escenarios críticos en los que actualizaciones de software han dejado a sus clientes “fritos”, es decir, con sus sistemas inoperables o expuestos a amenazas.
Es necesario mencionar otros incidentes que han causado grandes problemas. A continuación, recordaremos algunos casos con alto impacto y las consecuencias de tales eventos:
- Caso AVG (2012)
En 2012, AVG, un popular software antivirus, protagonizó un incidente que dejó a miles de usuarios con sus equipos inoperables. La actualización del software identificó erróneamente archivos legítimos del sistema operativo Windows como malware, procediendo a su eliminación.
Las consecuencias fueron devastadoras. La eliminación de archivos críticos provocó fallos graves en el sistema, dejando inutilizables los ordenadores de muchos usuarios.
- Caso WebRoot (2017)
WebRoot protagonizó un incidente de seguridad de proporciones considerables, tras una actualización rutinaria de su software antivirus, un error catastrófico provocó que el programa identificara por error archivos esenciales del sistema operativo Windows como malware. Este fallo, que afectó principalmente a sistemas Windows 2008 R2 y Windows 7, tuvo consecuencias nefastas. La empresa perdió una gran cantidad de clientes y su reputación quedó seriamente dañada.
- Sophos Antivirus y Windows 11 (2022):
En mayo de 2022, una actualización de Windows 11 (KB5013943) generó incompatibilidades con el software Sophos Antivirus, causando BSOD y reinicios inesperados en dispositivos que ejecutaban ambos programas.
Conclusiones
El incidente de CrowdStrike nos deja importantes lecciones que aprender:
- La necesidad de pruebas de software rigurosas: Este incidente es un claro recordatorio de que las pruebas de software son cruciales para prevenir errores graves. Las empresas deben invertir en pruebas exhaustivas que incluyan una variedad de escenarios y dispositivos para detectar y corregir errores antes de que se publiquen las actualizaciones.
- La importancia de la transparencia y la comunicación: CrowdStrike actuó con rapidez y transparencia para comunicar el problema a sus clientes y proporcionar soluciones. Esta es una práctica esencial para minimizar el impacto de los errores y mantener la confianza de los usuarios.
- La necesidad de un enfoque proactivo para la ciberseguridad: Las empresas deben ir más allá de las medidas de seguridad tradicionales y adoptar un enfoque proactivo para la ciberseguridad. Esto incluye la implementación de controles de seguridad en capas, la realización de pruebas de penetración regulares y la capacitación continua de los empleados en materia de seguridad cibernética.
En el caso específico de CrowdStrike, las siguientes lecciones son especialmente relevantes:
- La importancia de la diversidad en las soluciones de ciberseguridad: No se debe depender de un solo proveedor de soluciones de ciberseguridad. Es recomendable utilizar una combinación de soluciones de diferentes proveedores para reducir el riesgo de que un fallo en un solo sistema afecte a toda la organización.
- La necesidad de planes de respuesta a incidentes sólidos: Las empresas deben tener planes de respuesta a incidentes bien definidos y probados para poder responder de manera rápida y efectiva a eventos cibernéticos.
- La importancia de la vigilancia constante: Las empresas deben monitorear continuamente sus sistemas para detectar y responder rápidamente a cualquier actividad sospechosa.
Desde Ciberso, ayudamos a nuestros clientes con metodologías innovadoras basándose en las ya conocidas DevSecOps donde colaboramos a que este tipo de problemas se queden en entornos previos para evitar que ocurran en producción, si estás interesado en saber cómo podemos introducir estos controles no dudes en contactar con nosotros… ¡Te esperamos!

Publicaciones Relacionadas




Solicita más información
Si necesitas contactar con nosotros puedes rellenar formulario a continuación. Nos pondremos en contacto contigo lo antes posible.